
어떤 요소를 추상화하는 기본적인 개념이 2가지가 있다.
1. Process abstraction
함수와 같이 어떤 기능(절차)의 추상화를 말한다.
2. Data abstraction
객체지향 프로그래밍의 클래스같이 데이터를 하나로 추상화하는 것을 말한다.
이번 글에서는 process abstraction에 대해서 더 깊게 파보자.
Subprogram
서브프로그램은 말 그대로 프로그램을 구성하는 하위 프로그램이다.
서브 프로그램은 반드시 맨 처음부터 시작한다. (중간부터 시작x)
즉, 진입점이 하나밖에 없는 single entry point 를 가진다.
프로그램을 호출하는 프로그램을 caller, 호출당하는 프로그램을 callee 라고 한다.
callee가 실행되는 동안에는 caller가 멈춰있고, callee가 실행을 끝내면 이때 caller 가 이어서 작업을 한다.
서브프로그램을 작성하는 것을 subprogram definition 이라고 한다.
정의할 때는 서브프로그램 header 파트가 있다.
이 파트에는 서브프로그램 이름, 서브프로그램이 필요로 하는 파라미터와 타입, 반환 타입들을 갖고 있는다.
다른 말로 parameter profile (signature), protocol을 정의한다고 말하기도 한다.
(어떤 걸 주면 어떤걸 반환하겠다는 약속을 정하는 것이므로)
서브 프로그램을 호출할 땐, 이 parameter profile, protocol을 보고 호출한다.
C/C++에서는 함수 정의를 prototypes 라고도 말한다.
subprogram declaration 은 함수의 protocol만 제공하고 body를 주지 않는 것을 말한다.
(C언어에서 상단에 한 줄만 쓰는 그거)
Parameter
파라미터에는 formal parameter, actual parameter 가 있다.
formal parameter 는 서브프로그램 헤더에 정의된 더비 변수로, 함수 내에서 사용된다.
actual parameter 는 실제로 사용되는 값/주소값을 나타낸다.
이때 actual parameter 와 formal parameter를 매칭하는 방식에 2가지가 있다.
1. positional : 파라미터의 위치로 매핑한다. 파라미터가 많아지면 힘들다는 단점이 있지만 안전하고 효과적이다.
2. keyword : 파라미터 이름을 키워드로 지정해서 값을 넘기는 방법이다. 모든 파라미터 중 일부에만 값을 넘길 수 있다.
이 경우 값을 받지 않은 파라미터에 대해서는 default 값을 고민해야 한다.
C++, python, ruby, php 와 같은 언어는 formal parameter 가 디폴트 값을 가질 수 있다.
하지만 C++은 키워드 파라미터가 없어서 뒤에서부터 디폴트값을 주어야 한다.
파라미터 변수의 개수를 가변으로 두는 것도 가능하다.
C# 은 params 라는 키워드를 이용해 선언한 formal parameter에 여러개의 값을 넘길 수 있도록 한다.
(C에서는 ``` 에 해당한다. ellipsyse)
이런 경우에는 각 파라미터에 넘어온 값들을 스택에 순서대로 넣어서 보낸다.
Procedure
어떤 언어에서는 함수와 구분하여 프로시져를 두는 경우도 있다.
함수는 파라미터를 갖고 뭔가 연산한 뒤 return value를 돌려준다.
프로시저는 파라미터를 갖고 뭔가 연산한 뒤, 파라미터에 바뀐 값을 넣어서 돌려준다.
따라서 return value 가 여러개 들어올 수 있다.
프로시저를 사용하면 애초에 사이드 이펙트가 있다는 것을 생각하고, 사이드이펙트를 이용해 값을 주고받겠다는 것을 말한다.
함수의 경우에는 사이드 이펙트를 좀 줄이고, reference transparency를 높이는 것을 목표로 한다.
Design Issue
서브프로그램을 언어에서 디자인할 때 고려해야 하는 사항들은 굉장히 많다.
이 중 일부에 대해 살펴보자.
Local Variable 의 referencing envrionment
지역 변수는 static 인가 dynamic 인가 고민해야 한다.
보통은 stack-dynamic 이다.
서브 프로그램을 위한 스택 공간을 따로 만들어서 거기에 지역 변수를 할당하는 것이다.
이렇게 하면 재귀도 가능해지고, caller-callee 사이에 통신도 가능해지는 장점이 생긴다.
하지만 런타임에 스택을 초기화하고, push, pop 하는 시간이 추가되기 때문에 실행 시간이 느려지는 단점이 생긴다.
또 스택을 얼마나 할당할지 모르기 때문에 주소를 미리미리 계산할 수 없고, 스택의 시작점으로부터 어디까지 오프셋으로 계산하므로 주소값 계산이 복잡해진다.
마지막으로 서브프로그램이 종료되면 stack에서 pop되면서 갖고 있던 변수값이 모두 사라지기 때문에, history sensitive 할 수 없다.
이런 문제를 해결하고자 static을 사용하게 되면 재귀를 할 수 없는 문제가 생긴다.
(위에서 설명한 장단점이 반대로 바뀐다.)
그래서 대부분 언어에서 지역변수는 stack-dynamic 이고, C언어 계열은 static 선언도 허용해준다.
단, C++, Java, Python, C#의 메소드는 stack-dynamic 방식만 사용한다.
Parameter Passing
파라미터에 값을 넘기는 방법에 대해 고민해보자.
이 방법은 크게 3가지로 분류된다.
In mode : 콜리에게 이 값이 actual parameter니까 가져다가 계산하라고 주는 것이다.
Out mode : 콜리가 계산한 값을 파라미터를 통해 넘기는 경우, 이를 out mode라고 한다.
Inout mode : 이때 in, out을 모두 허용하는 경우를 inout mode 라고 한다.
넘기기만 할 수 있냐, 받기만 할 수 있냐, 넘기고 받을 수도 있냐의 차이다.
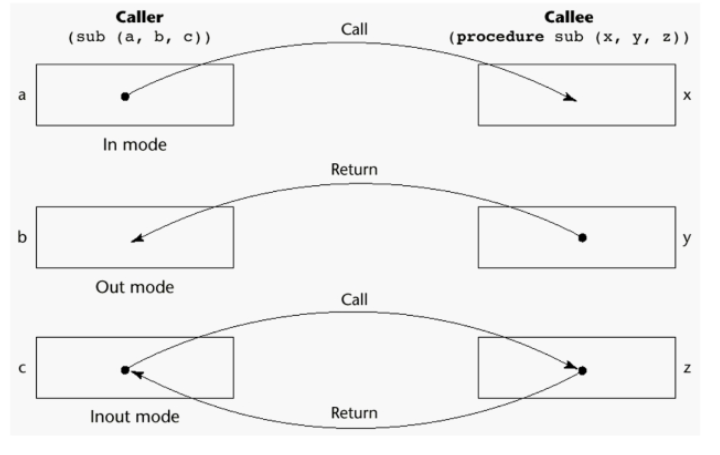
그림으로 보면 위와 같다.
그렇다면 어떻게 actual parameter 를 넘겨줄까?
크게 값을 몽땅 복사해서 넘기거나, actual parameter 에 접근할 수 있는 방법을 주는 경우로 분류된다.
(move a value / move an access path to a value)
Pass-by-Value (In Mode)
in mode, 즉, 서브프로그램에 값을 전달하기만 한다. Call-By-Value 라고도 한다.
값을 카피해서 보내는 방식이다.
문제는 값을 카피할 주소 공간이 확실히 필요하고, 그 공간이 클 수록 카피하는 시간도 오래 걸린다.
값을 카피하는 과정에서 메모리가 전기를 많이 쓰는 문제도 있다.
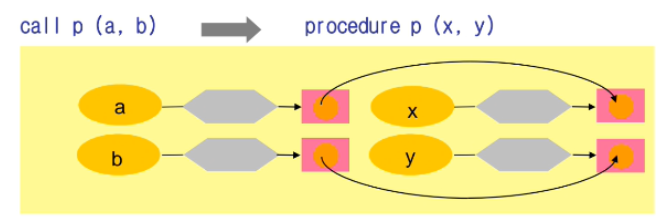
그림으로 보면 위와 같다.
육각형은 변수의 attribute를 의미한다.
빨간색 네모는 실제 메모리에 있는 값을 의미한다.
call 하면 a, b 의 값을 복사해서 formal parameter x, y 에 넣는다.
이 값은 절대 변하지 않기 때문에 referential transparency 를 확실히 할 수 있다.
또 프로시저 입장에서는 사실상 formal parameter 를 지역 변수처럼 쓸 수 있게 된다.
그럼 연산 결과는 어떻게 돌려줘야 할까?
Pass-by-Result (Out Mode)
그래서 이때는 result 를 받는 파라미터를 통해 연산 결과를 돌려준다. 돌려주기만 하므로 out mode 이다.
돌려줄 때도 연산결과 값을 복사해서 돌려준다.
그런데 이때 두가지 잠재적인 문제가 있다.
1. 원래 없던 값을 가지고 계산해서 돌려주는 값이 아닌가?
2. 콜리가 계산해서 준 값을 받았을 때, 아까 준 값을 써야하나 바뀐 값을 써야하나 모르는 문제
그래서 이 문제를 해결하기 위해 call by value, call by result를 합치는 방법이 등장했다.
Pass-by-Result (Inout Mode)
pass-by-copy 라고도 부른다.
이렇게 하니 값이 돌아온다는 장점은 있지만, 합친 둘의 단점도 모두 갖는다.
그래서 다른 방식이 등장했다.
Pass-by-Reference (Inout Mode)
access path 를 전달하는 방식이다. (포인터 전달)
그래서 데이터를 공유하게 만든다.
주소만 넘기면 되니 공간도 적게 쓰는 장점이 있다.
(by-address, by-locaton 등등 다양하게 부른다.)
하지만 항상 포인터를 통해서 값을 바꿔야 하기에 access가 느리다.
포인터가 갖고 있는 문제들도 모두 갖는다. (danggling point, garbage)
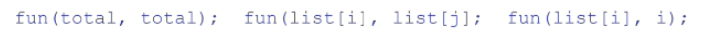
포인터를 줘서 값을 바꿨을 때 값을 리턴하려고 하니 그럼 이 변수는 아까랑 똑같은 건지 새로 바뀐 건지 알 수 없다.
call-by-value, call-by-result 의 문제가 해결되지 않았다.
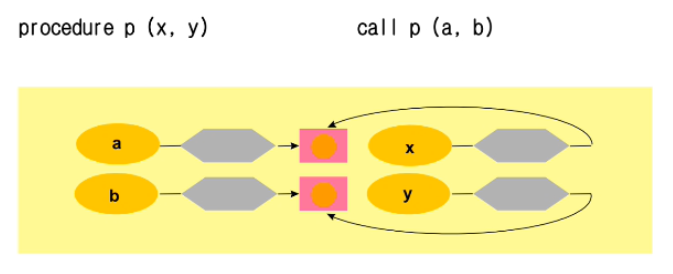
그림으로는 위와 같다. x의 attribute에 실 매개변수의 주소가 들어오니 이를 통해 연산한 값을 바로 메모리에 쓴다.
또 다른 문제는 매개변수로 넘어온 주소값을 바꿀 수 있는지에 대한 문제다.
C언어는 이를 허용한다.
그러나 파스칼, C++ 과 같은 언어는 formal parameter 에 값을 쓰면 안되는 경우를 명확하게 구분해준다.
Call-By-Name (Inout Mode)
그래서 어떤 사람이 값을 넘겨도 문제, 주소를 넘겨도 문제라면 그냥 코드를 그대로 바꿔서 복사해주면 어떨까 하는 생각을 했다.
이걸 구현하려면 컴파일러에 미리미리 복사 구조를 다 만들어 놔야하니 간단한 문제가 아니다.

위 예제를 보자.
X, Y 의 값을 교환하는 프로시저가 있다.
TEMP 라는 정수 변수가 함수 내에 있고, 이를 경유해서 X, Y 의 값을 바꾼다.
만약 j = 3 이라고 하면
3과 n[3] 을 교환하게 되는데, 매개변수로 넘어온 j 라는 이름 자체를 그대로 활용해서 교환을 진행하므로
j 라는 변수에 있는 값을 temp 에 넣어서 temp 에는 3이 들어가고
n(3)의 값을 j 에 넣어서 저장하니 j에는 1이 저장된다.
그런데 마지막으로 temp 의 값을 n(j)에 저장힐 때는 j에 저장된 1이라는 값을 그대로 사용해서
temp 의 값을 n(1) 에 저장하는 문제가 생긴다.
즉, j는 변수 '이름' 이고, 이 변수의 값을 j0 이라고 하면 오른쪽 아래와 같은 동작으로 진행된다.
결론은 어떤 파라미터 패싱 기법을 사용해도 문제가 생기니 프로그래머가 충분히 주의를 해야 한다.
실제로 파라미터를 줄 때는 런타임 스택에 넣어서 준다.
그래서 제일 간단한 방법은 pass by reference 이다.
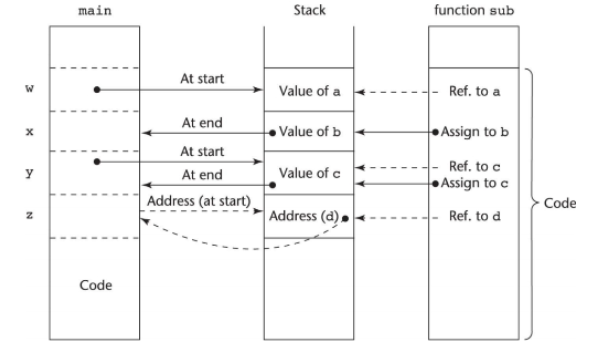
처음 main 이 sub 라는 함수를 호출하면 w, x, y값을 넘겨야 하는데, 받는 측에서 callee 는 a, b, c, d 라는 formal 파라미터로 받는다.
w 값을 스택에 저장한 뒤, sub에게 알려주면 서브가 a라는 값을 참조한다. (in mode)
x 라는 값은 sub 가 b에 값을 assign 해서 스택에 저장하면 그 값이 나중에 x로 나온다. (out mode)
y 값을 스택이 제정한 뒤, sub 에게 알려주면 sub가 c에 대한 참조롤 보고 계산해서 값을 c에 할당하면 y로 결과 값이 나온다. (in out mode)
z 는 처음에 z에 대한 주소값을 주면, 스택에 주소값이 들어있다. sub는 이 주소값에 대한 참조를 갖고 있어서 바로 z에 접근할 수 있다.
언어별 파라미터 모드
C언어는 call by value, call by reference 모두 가능하다. (포인터 사용)
C++은 참조 타입을 이용해서 call by reference 를 할 수 있다.
자바는 모든 오브젝트가 아닌 타입은 call by value로, 오브젝트는 call by reference로 넘어간다.
포트란은 3가지 구분 in, out, inout 모두 가능하다.
C#은 기본적으론 call by value 지만, ref 키워드를 사용하면 call by reference 도 가능하다.
swift 는 inout 키워드를 사용해서 주고받기가 가능하다.
ada는 3가지 구분을 모두 쓸 수 있찌만, 펑션에 들어가는 파라미터는 in밖에 안된다.
펑션에서 갖고 간 값을 마음대로 바꾸는 것은 reference transparency가 깨지기 때문이다.
Type Checking Parameter
파라미터의 타입과 파라미터에 들어간 값의 타입을 확인하는 것을 말한다.
하는 언어도 있고 안하는 언어도 있는데, 오리지널 C는 하지 않았다.
중간에 타입 체크 필요성이 생겨서 per, javascript php 는 인터프리터가 타입체킹을 해주는 것으로 하다가 최신 언어게 가니 타입이라는게 아예 없어서 체킹할 필요가 없다고 한다.
다차원배열 파라미터
다차원 배열을 매개변수로 보내면 그 크기가 크니 많은 복사가 필요하다.
따라서 컴파일러는 이 배열의 크기가 얼마나 되는지를 미리미리 체크해야 한다.
이 값들은 descriptor 에 들어 있다. 따라서 배열의 값 뿐만 아니라 array의 descriptor 까지 카피를 해줘야 한다.
이 문제 때문에 C/C++은 그냥 포인터를 넘겨주고 끝낸다.
근데 ada는 진짜 다차원 배열도 주고받을 수 있다. C#, Java도 지원을 한다.
종합적으로 파라미터 패싱에 대해 고민할 필요가 있는 내용은 다음과 같다.
1. 얼마나 빠른 속도로 파라미터 패싱이 가능한가 (efficiency)
2. 안전성, 즉, reference transparency를 보장해야 하는가, 에러를 어떻게 할 것인가, 타입체크를 어떻게 할 것인가.
3. in, out, inout 어떤 걸 허용할 것인가
Subprogram 을 파라미터에 넘기기
이때 발생할 수 있는 고민거리는 2가지다.
1. 파라미터 타입이 체크되는가?
2. 파라미터로 보낸 서브프로그램의 referencing environment 는 어떻게 되는가
서브 프로그램의 참조 환경에 대해서는 크게 3가지로 구분된다.
1. shallow binding : dynamic - scoped language 처럼 행동한다.
2. deep binding : static scope langeuage 처럼 행동한다.
3. ad hoc binding
서브 프로그램을 간접적으로 호출하는 (파라미터로 넘기는) 방법이 있긴하다.
C/C++의 함수 포인터를 넘기는 방법이다.
물론 너무 복잡하고 위험해서 잘 사용하지는 않는다.
C#에서는 메소드 포인터가 있다. (delegate 라고도 부른다.)
delegate를 아예 선언할 수도 있다.
이를 통해 함수를 instantiate 해서 호출하거나 넘길 수도 있다.
정말 가끔 delegate가 여러개의 주소를 가질 수도 있는데 이를 multicast delegate라고 부른다.
함수에 대한 설계 고민
서브프로그램이 한 일을 물려받는 방법은 함수가 뭔가를 돌려주는 것과 같다.
즉, 함수 외부에 있는 변수 값을 바꿔달라는 뜻이라, reference transparency를 위반하면서 사이드 이펙트가 생길 수 있다.
그래서 사이드 이펙트를 허용할 것인지, 아니면 ada 처럼 허용하지 않도록 in-mode 만 쓰도록 할 것인지 결정해야 한다.
또 return value의 타입도 고민해야 한다.
함수를 받아서 함수를 돌려주는 경우도 있을 수 있기 때문이다.
C++은 사용자 정의 타입도 반환할 수 있다.
자바와 C#은 메소드는 타입이 아니라서 리턴할 수 없지만, 나머지는 리턴할 수 있다.
파이썬, 루비는 메소드를 first-calss object로 다루기 때문에, 다른 클래스처럼 리턴할 수 있다.
Subprogrm 오버로딩
서브프로그램 오버로드는 같은 이름의 서브프로그램이 여러 동작을 할 수 있도록 하는 것을 말한다.
예를 들면, 배열에서 최댓값을 찾아주는 함수인데 타입만 int, long 과 같이 변하는 것이다.
동작은 같은데 타입만 달라진다.
첫번째로, 이름만 같고, 펑션 프로토타입까지 다른 경우가 있을 수 있다.
Ada, C++, C#, Java는 미리 정의된 오버로딩된 서브프로그램을 쓸 수 있게 지원한다.
ada는 거기에 컴파일러가 알아서 타입까지 맞춰주는 기능을 제공한다.
두번째로 함수의 기본 기능은 동일한데 타입만 다른 경우가 있다.
이를 generic , 또는 polymorphic subprogram 이라고 한다.
타입 자체를 매개변수화하는 ad hoc polymorphism 을 제공한다.
(type parameterization) 이를 가리켜 parametric polymorphism 이라고도 한다.
C++의 템플릿이 이에 해당한다.
자바에서는 Collection 이 이에 해당한다.
C#은 와일드카드를 지원하지는 않지만, 컴파일러가 타입을 확인할 수 있으면 자동으로 해준다.
F#은 제네릭 타입을 아직 결정하지 못했을 때, automatic generalization 을 통해 자동으로 타입을 나중에 결정해줄 수 있다. 이를 위해 'a 와 같이 쓰면 any type이라는 의미로 아무 타입이나 파라미터로 받을 수 있게 된다.
물론 정말 아무 타입이나 막 쓸 순 없다. 문자열 곱셈과 같은 기능은 할 수 없기 때문이다.
그래서 타입에 제한을 두도록 디자인했다.
Closure
클로저는 서브프로그램과 그 서브프로그램의 참조 환경까지 지정해주는 것을 말한다.
static scope language, 중첩된 서브프로그램을 지원하지 않으면 클로저는 필요가 없다.

위 그림과 같이 여러 함수를 중첩해서 선언하고, D를 선언했을 때, D가 A, B의 변수를 non-local variable 로 사용할 때, 이 변수 값 자체를 참조 환경으로서 가져다 주는 것을 클로저라고 한다.

클로저의 예시는 위와 같다.
makeAdder(x) 를 호출하면, 어떤 function(y)를 호출해준다.
이 함수는 내부적으로 x를 사용하는데, 이 x의 값이 makeAdder(x)로 넘어온 값으로 고정되어있다.
즉, function(y)를 반환할 때 x라는 값이 참조환경으로서 같이 반환되어 이미 적용된채로 넘어오는 것이다.
C#에서는 delegate (위임자) 개념을 이용해서 클로저를 만들 수 있다.
Coroutine

서브루틴 2개가 있을 때, 하나의 서브루틴이 조금 실행하고, B한테 이어서 실행하라고 넘겨주고,
B가 다시 조금 실행하고 마저 A에게 실행하라고 하면 A가 마저 실행하는 것을 반복한다.
즉 두 함수가 서로 합을 맞춰서 번갈아 실행하는 것을 말한다.
이 과정이 빠르게 일어나면 겉보기에 마치 두 함수가 동시에 실행되는 것처럼 보일 수 있다.
(quasi-concurrent execution)
이를 가리켜 symantic control 이라고도 부른다.
resume을 해야 상대방에게 컨트롤을 넘길 수 있다.
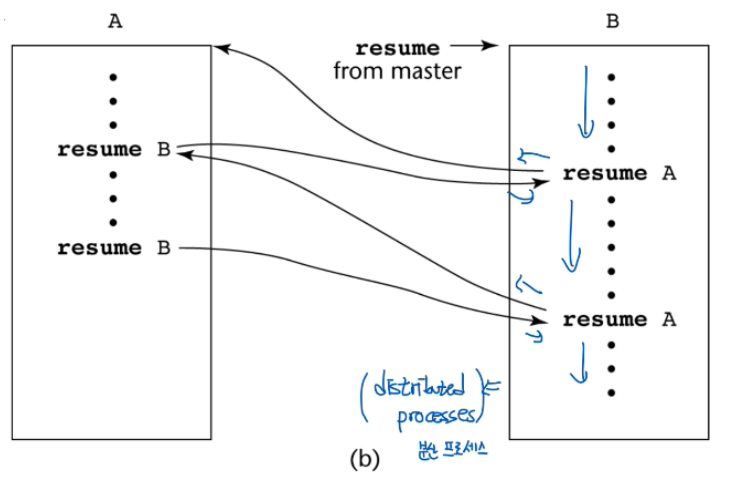
이때, A, B가 정말 동시에 진행되면 이를 distributed process 라고 한다. (분산 프로세스)
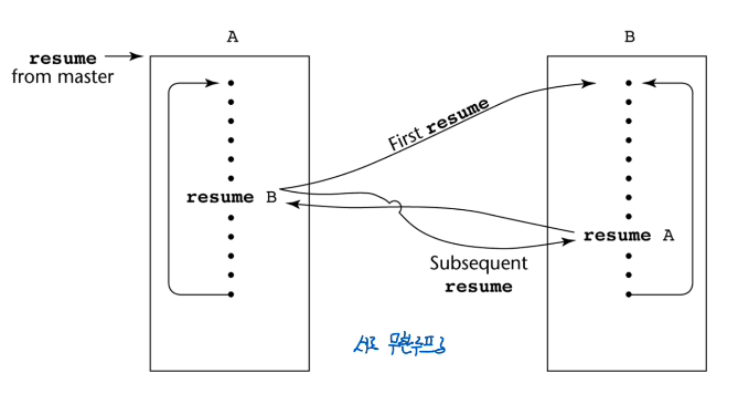
정리하면
서브 프로그램은 기능에 대한 추상화를 말한다.
그리고 함수, 프로시저 2개로 분리할 수 있었다.
서브 프로그램의 변수는 stack-dynamic 하게 만들어도 되고 static 하게 만들어도 되는데 각각 장단점이 있었다.
파라미터를 보낼 때는 in, out, inout 3가지로 보낼 수 있었다.
연산자 오버로딩, 서브프로그램 오버로딩, 제네릭 서브프로그램의 개념이 있었고,
서브프로그램에 참조 환경까지 추가해준 것을 클로저라고 했다.
마지막으로 코루틴은 여러 entry를 가진 서브프로그램을 말했다.
Example

이 프로시저에 대해, call by value, call by name, call by reference로 호출 했을 때 실행 결과를 정리해보자.
우선 보기 쉽게 코드를 고쳐보자...
void P() {
int A[3], I;
I = 1;
A[1] = 2;
A[2] = 4;
Q( A[I] );
void Q (int B) {
A[I] = 3;
I = 2;
print(B);
}
}
1. call by value
I = 1 이고, A[1] = 2 이므로,
Q( A[I] ) 는 Q(2) 와 같다. (값을 복사해서 넘긴다.)
Q 내부적으로 봤을 때, B는 2라는 복사된 값을 받는다.
A[I] 는 모두 논 로컬 변수로서 A 밖에서 참조하므로, A[I] = 3 을 하면 당연히 A[1] 값이 3으로 바뀐다.
I = 2 로 하면 밖에 있는 논 로컬 변수 I의 값이 3으로 바뀐다.
이때 print(B)를 하면 2가 출력된다.
2. call by name
정말 'A[I]' 라는 이름을 넘긴 것이다.
위에서 정리했던 call by name 예제를 보면
함수 내 코드 X, Y 에 정말로 J, N(J) 를 넣고 실행하는 것과 같다.
그러면 주어진 Q 함수 내부는 다음과 같이 바뀐다.
void P() {
int A[3], I;
I = 1;
A[1] = 2;
A[2] = 4;
Q( A[I] );
void Q (int B) { // B로 A[I]가 넘어오므로
A[I] = 3;
I = 2;
print(A[I]); // 여기가 A[I] 로 바뀐다.
}
}
정말로 B 대신에 넘어온 코드 A[I] 를 사용하는 것!
그러면 A[I] 에 3이라는 값을 대입하고 (I = 1 이므로 A[1] = 3)
I = 2 를 대입했으니 바뀌고
A[I] 를 호출하면 A[2] 를 출력하라는 것과 같으니
4가 출력될 것이다.
3. call by reference
값을 넘길 때 A[I] 의 주소값을 넘긴다는 뜻이다.
B에는 A[I]의 주소값(참조)이 들어있으므로, A[I] 에 대해 발생한 모든 조작은 B가 그대로 인지하게 된다.
따라서 Q 내부에서 A[I] 를 3으로 바꾸면 이때 A[I]는 3이 저장되고, B는 같은 A[I]를 바라보고 있기 때문에
이때 B를 출력하면 3이 출력될 것이다.
Example 2

void P() {
int A;
A = 1;
Q(A);
void Q(B) {
int A, B;
A = 2;
print(B);
}
}
1. call by reference
Q의 B로 A 의 참조가 전달되었다.
그런데 매개변수 B를 Q의 지역변수 B가 덮어 써버렸다.
그러면 무슨 값이 출력될까....
지역변수 B가 매개변수를 덮어쓴다면 알 수 없는 값이 나오는 것이 맞고,
지역변수 B와 무관하게 사용한다면 1이 나올 텐데...
덮어쓰는게 맞는 것 같다.
그래서
2. Call by Value
3. Call by Name
모두 알 수 없는 값이 나올 것으로 예상한다.
(근데 진짜 모르겠다. GPT도 틀리는 듯..)
Example 3

1. call by value
v[k] 를 매개변수로 넘기면, v[4] 의 값이 넘어가므로 8이 넘어간다.
하지만 매개변수가 지역 변수 a에 의해 가려지므로, 넘어온 값을 활용할 수 없다.
지역변수 a에는 미정의 값이 들어있다.
이때 함수 내에서 v[k]를 조작하면 외부에 있는 v, k 를 가리키므로 v[4]를 조작하게 되어 v[4] = 5 가 실행되고,
k = 3 이 실행된다.
따라서
v[3] = 6
v[4] = 5
2. call by Reference
마찬가지로 a가 가려지기 때문에 같은 결과가 발생한다.
v[3] = 6
v[4] = 5
3. call by result
매개변수 a에는 a를 통해 연산한 값이 return 될 뿐이다.
하지만 미정의 값에 대해 조작하고 있으니 a는 v, k에 아무런 영향을 주지 않는다.
따라서 같은 결과가 발생한다.
v[3] = 6
v[4] = 5
4. call by value result
a는 값을 받기도 하고, 내뱉기도 하는 용도로 쓰인다.
값을 복사해서 받을 때는 8을 받지만 내부 지역변수에 의해 a가 가려지고
쓰레기 값들이 연산된 후에 P(a)로 복사해서 돌려준다.
당연히 함수 내부에서는 아무런 영향을 받지 않았기 때문에 결과는 같다.
v[3] = 6
v[4] = 5
5. call by name
a로 v[k] 라는 이름이 그대로 들어온다.
하지만 내부에서 a를 다른 지역변수로 덮어 써버렸기 때문에 a를 v[k]로 치환할 수 없다.
따라서 마찬가지 결과가 나온다...
v[3] = 6
v[4] = 5
이게 맞나..?
'CS > 프로그래밍언어론' 카테고리의 다른 글
| [프로그래밍언어론] 12. Expression & Assignment Statements (0) | 2024.06.13 |
|---|---|
| [프로그래밍언어론] 11. Logic Programming Language (Prolog) (0) | 2024.06.13 |
| [프로그래밍언어론] 10. Data Type (0) | 2024.06.13 |
| [프로그래밍언어론] 9. 함수형 언어 (LISP) (0) | 2024.06.12 |
| [프로그래밍언어론] 8. Name & Binding (0) | 2024.06.12 |