
Virtual vs Real vs Transparent vs Erase
1978년 IBM에서 정의한 바에 따르면
실제로 존재하는데, 눈으로 볼 수 있으면 'Real' 이라고 한다. (현실)
실제로 존재하는데, 눈으로 볼 수 없으면 'Transparent' 라고 한다. (투명하다)
실제로 존재하지 않는데, 눈으로 볼 수 있으면 'Virtual' 이라고 한다. (가상)
실제로 존재하지 않는데, 눈으로 볼 수 없으면 'Erase' 라고 한다. (삭제했다)
따라서 이 용어에 따르면, Virtual Memory 는 실제로 존재하지 않지만 눈으로는 보이는 메모리를 일컫는다.
Virtual Memory
버추얼 메모리는 실제로는 운영체제가 제공하는 테크닉에 해당한다.
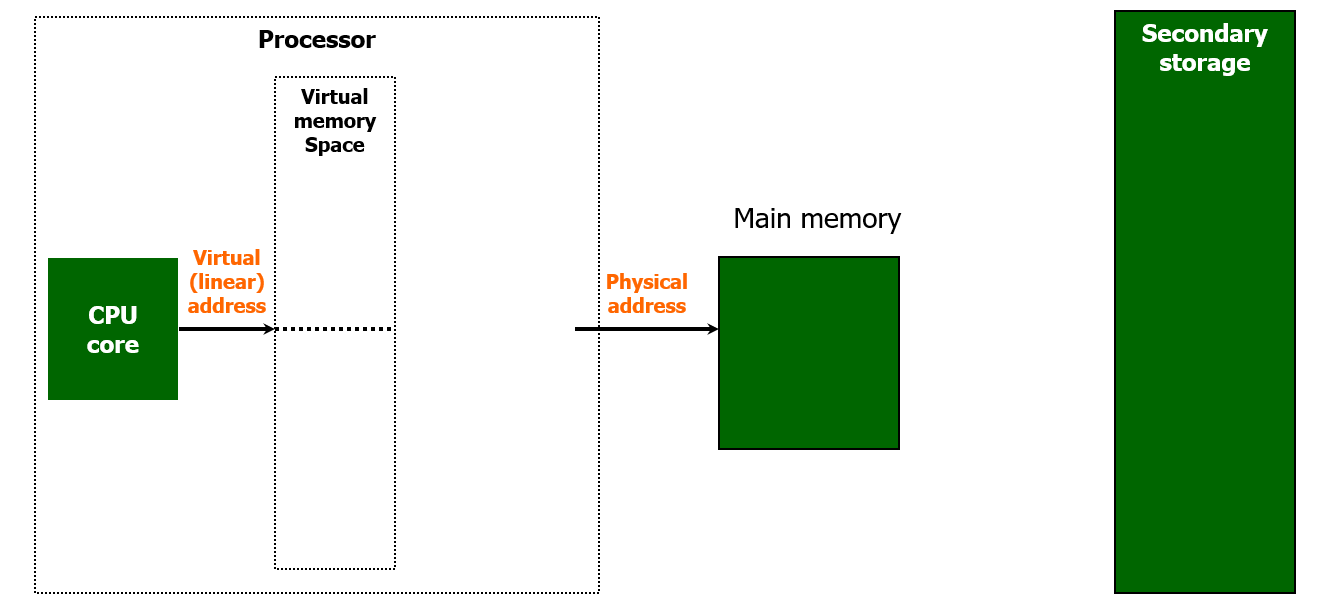
위 그림에서 초록색으로 표시된 장치는 실제로 존재하는 (Real) 장치를 말한다.
CPU Core 옆에 가상 메모리 공간을 두었다.
가상 메모리는 실제로 존재하지는 않지만, 가상으로 있다고 믿고, 존재하는 것이다.
이때 가상 메모리는 실제 메모리가 아니기 때문에, 가상 메모리에서 사용할 주소가 별도로 필요하다.
가상 메모리의 주소를 Virtual Address, 실제 메모리에서 사용하는 주소를 Physical Address 라고 한다.
(그리고 앞으로 메인 메모리는 Physical Memory 라는 이름으로도 사용한다.)
Virtual Address 는 말 그대로 가상 메모리 내부의 특정 공간을 가리킨다.
사실 지금까지 운영체제가 설치되어 있는 프로그램 상황 내에서 프로그램을 작성했을 때, 프로그래머가 작성하는 모든 주소는 'Virtual Address' 이다.
이 주소는 (이 메모리는) 가짜 주소라서 실제 데이터가 담길 수 없다.
따라서 이 주소는 physical address로 바뀐 뒤, 실제 메모리 공간을 가리켜서 데이터를 저장한다.
그리고 이렇게 Virtual Memory 라는 테크닉을 사용하면, 결과적으로 메인 메모리를 secondary storage 에 대한 캐시로 다루는 것과 같은 효과를 내게 된다.
Virtual Memory를 사용하는 이유
1. 물리적인 Main Memory가 복수개의 프로그램을 공유한다.
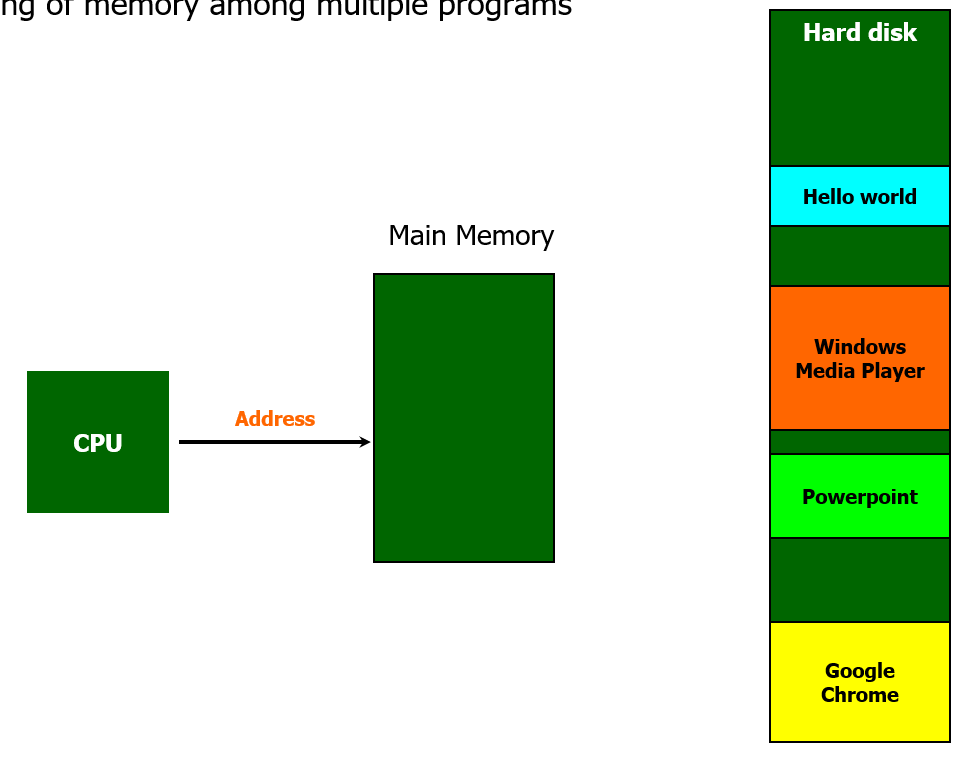
위 그림과 같이 가상 메모리가 없는 단순한 구조의 컴퓨터를 생각해보자.
하드 디스크에는 다양한 프로그램의 실행파일이 저장되어 있다.
이 프로그램들을 실행하려면 프로그램의 전체 또는 일부를 Main Memory에 올린뒤, CPU에서 명령어를 하나씩 읽도록 해야 한다.
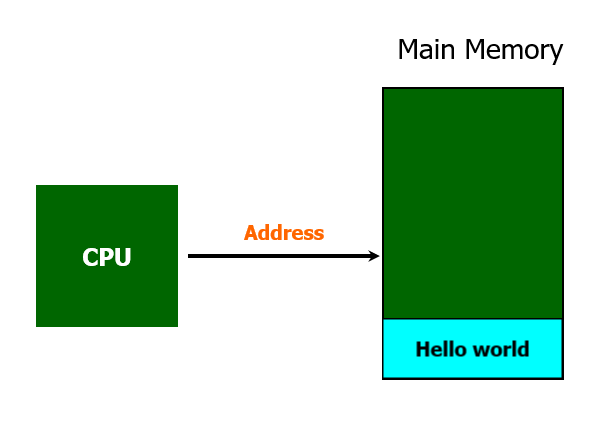
만약 Hello World 라는 프로그램을 실행하면, 해당 프로그램 데이터가 전체 또는 일부 복사되어 Main Memory에 적재된다.
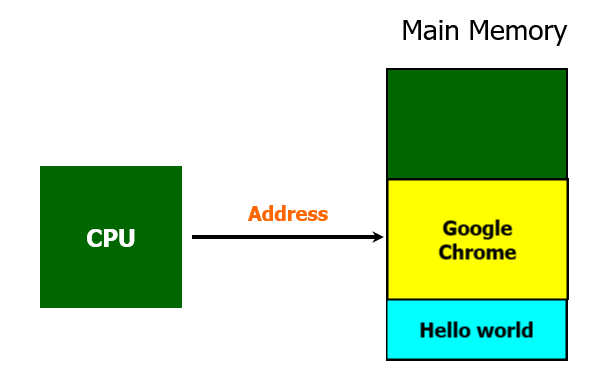
프로그램을 실행하던 도중에 검색을 하기 위해서 브라우저를 추가로 실행한다면, 구글 크롬과 같은 브라우저 프로그램도 메모리에 적재된다.
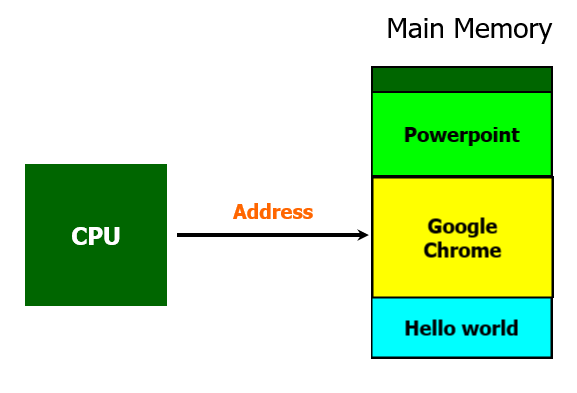
그랬다가 PPT를 만드려고 파워포인트를 실행하면 또 이렇게 적재되고,
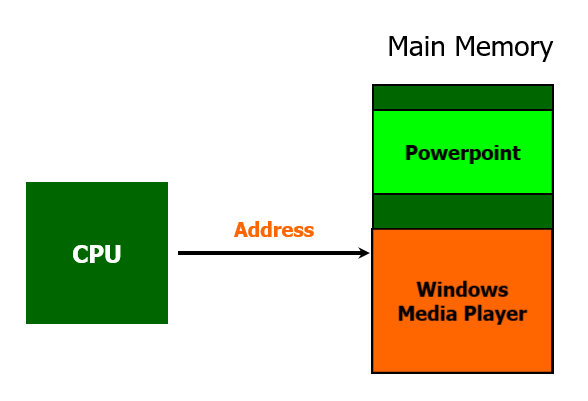
노래를 듣고 싶어서 Hello world 프로그램과 크롬을 닫고, 음악 재생 프로그램을 실행시킬 수도 있다.
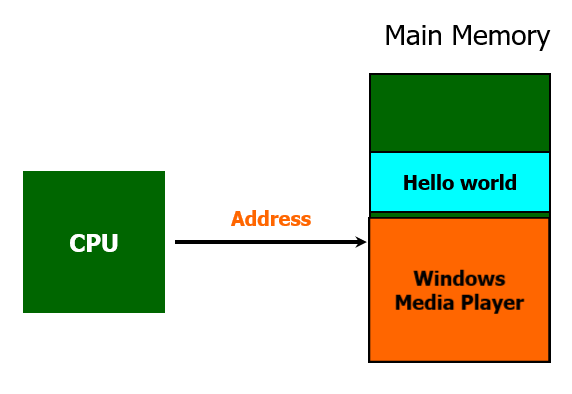
다시 PPT를 닫고, Hello world 프로그램을 실행한다고 해보자.
근데 이때 Hello world 프로그램에만 집중해보면, 처음에는 메모리의 맨 아래에 적재했었다가, 지금 실행할 때는 메모리의 중간 부분에 적재했다.
즉, hello word 라는 동일한 프로그램의 각 명령어를 실행하기 위해 가져오는 물리 주소가 그때그때 다를 수 있다.
이 현상은 하나의 메인 메모리를 여러 프로그램이 서로 공유하고 있기 때문에 발생한다.
그리고 각 프로그램들은 언제 어떻게 적재해서 사용할 지 알 수 없다.
프로그램의 실행은 그때그때 다이나믹하게 일어나는 상황이다.
따라서 내가 hello world 라는 프로그램의 코드를 작성할 때, 또는 이 코드를 기계어로 컴파일할 때는 미래에 실제 어떤 주소에서 이 프로그램이 실행될 지 알 수 없다.
이것이 가상 메모리가 필요한 첫번째 이유이다.
가상 메모리는 각각의 프로그램마다 자신만의 공간을 상상하는 것이다.
hello world 를 위한 가상 공간은 음악 플레이어, PPT 와 같은 다른 프로그램의 실행 공간을 생각하지 않고, 오로지 자신이 실행될 공간만을 생각한다.
이렇게 생각하면 프로그래머나 컴파일러 입장에서는 프로그램을 작성할 때 어떤 주소값을 사용할지 결정하는 것이 매우 편하다.
즉, 운영체제가 만든 virtual memory 라는 테크닉이 프로그램이 가정한 virtual address 를 physical address로 변환해준다.
2. 하나의 프로그램을 실행하는데 필요한 메모리 공간이 Main Memory 공간보다 클 수 있다.
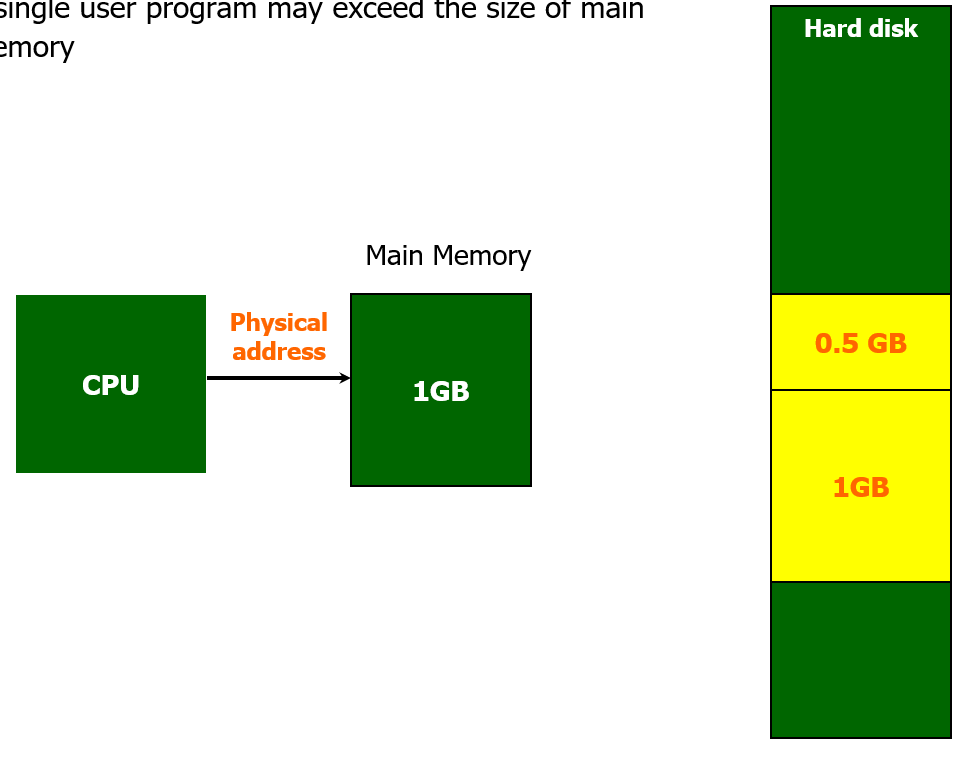
이번엔 그림과 같이 용량의 관점에서 같은 구조를 다시 바라보자.
Main Memory 는 1GB의 용량을 갖고 있다.
(지금보면 매우 작은 용량이지만, 과거 빌게이츠는 640kb면 충분하다고 말했었다고..)
만약 프로그래머 혹은 컴파일러가 자신이 만든 프로그램이 이 메모리 크기보다 크다면 프로그램의 일부분만 적재를 해야한다.
위 그림처럼 만약 1.5GB의 프로그램이 있다면
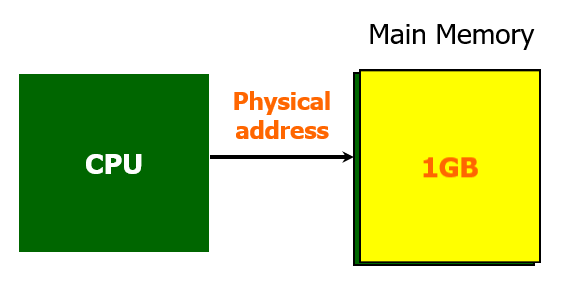
이렇게 1GB만 잘라서 먼저 적재해놓고 실행했다가
필요하면 나중에 0.5GB도 적재해서 실행하는 등, 중간중간 프로그램을 나눠서 실행하는 작업을 프로그래머 선에서 처리해야 하는 것이다.
(불가능하지 않지만 굉장히 생산성이 낮은 방법이다..)
그래서 요즘은 운영체제가 이 작업을 대신해준다.
우리는 프로그램을 만들 때 남은 메모리의 용량이 얼마인지 생각하면서 만들 필요가 없는 것이다.
그저 가상 공간에 충분한 공간이 있다고 생각하고 프로그램을 짜면, 운영체제가 가상 공간의 메모리 주소를 실제 메모리 주소로 알아서 매핑을 해주는 것이다.
이것이 가상 메모리 테크닉이다.
Page
가상 메모리는 위에서 적었듯, main memory를 secondary storage에 대한 캐시인 것처럼 동작시킬 수 있다.
그래서 진짜 캐시가 있고, 메인 메모리가 있는 계층이 하나, 메인 메모리가 있고, 세컨더리 스토리지가 있는 계층이 하나가 있어서 계속해서 캐시 역할을 하는 것과 같은 효과를 가지게 된다.
그리고 메인 메모리가 세컨더리 스토리지에 대한 캐시 역할을 한다는 것을 받아들인다면, 기존에 캐시와 메모리 사이에 주고받는 데이터 단위인 '블록' 과 같이, 메인 메모리와 세컨터리 스토리지 사이에 데이터를 주고받는 새로운 단위가 필요하다는 것을 떠올릴 수 있다. 그리고 이 단위를 '페이지' 라고 한다.
메인 메모리와 세컨더리 스토리지 사이에는 항상 '페이지' 단위로 데이터를 주고 받는다.
캐시 블록의 크기가 정해져있지 않은 것처럼, 페이지의 크기도 정확하게 정해져있지는 않다.
하지만 캐시 블록의 크기가 통상적으로 64byte 인 것처럼, 페이지는 통상적으로는 4kb 크기를 사용한다.
그리고 페이지가 있다면, 프로그램을 실행할 때, 실행에 꼭 필요한 페이지만 physical memory ( = main memory) 에 올려도 실행할 수 있다는 결론을 얻을 수 있다.
프로그램이 각각 자신이 가상으로 생각한 공간을 virtual space 라고 하는데, 이 공간은 4kb의 페이지들이 모여있는 컬렉션과 같은 공간으로도 생각할 수 있다.
사용자가 실제로 실행하는데 필요한 페이지는 항상 메모리에 올라가 있이면 좋을 것 같다.
하지만 마치 CPU가 원하는 블록이 캐시에 없으면 Miss가 발생하는 것처럼, 실행하는데 필요한 페이지가 메모리에 들어있지 않은 경우도 있다. 이런 경우를 Page Fault 라고 부른다. (Cache Miss의 페이지 버전)
이름만 보면 심각한 일이 발생한 것 같지만, 기능적으로는 CPU가 필요로하는 페이지가 메인 메모리에 없고 Secondary Stroage에 들어있다는 뜻을 의미하므로 실행이 불가능하다거나 그런 상황은 아니다.
캐시에서와 마찬가지로 세컨더리 스토리지에서 메인 메모리로 다시 페이지를 적재하면 된다.
Virtual Space를 여러 Virtual Page로 구분해두면, 특정 프로그램 입장에서는 특정한 Virtual Page를 가리키고 있을 것이다.
이때 프로그램을 실제로 실행하려면 Virtual Page를 실제 Physical Page로 매핑할 수 있어야 한다.
(마치 direct mapped 캐시에서 캐시 블록을 실제 메모리 블록과 매핑하는 것과 같다.)
이 매핑은 운영체제가 해주는데, 이때 page table 이라는 자료구조를 통해 매핑 정보를 관리한다.
페이지 테이블 안에는 virtual page를 physical page로 변환할 수 있는 정보가 포함되어있다.
예시
2개의 프로그램이 하나의 메인 메모리를 공유하는 상황을 생각해보자.

먼저 컴퓨터는 위와 같이 구성되어있다고 하자.
프로그램은 자신의 프로그램을 실행할 virtual address space를 생각하고 있으며, 이 공간은 4kb의 virtual page들로 조각조각 구분할 수있다. 이 공간은 자신만의 독립적인 가상 공간이므로 다른 프로그램을 생각할 필요가 없다.
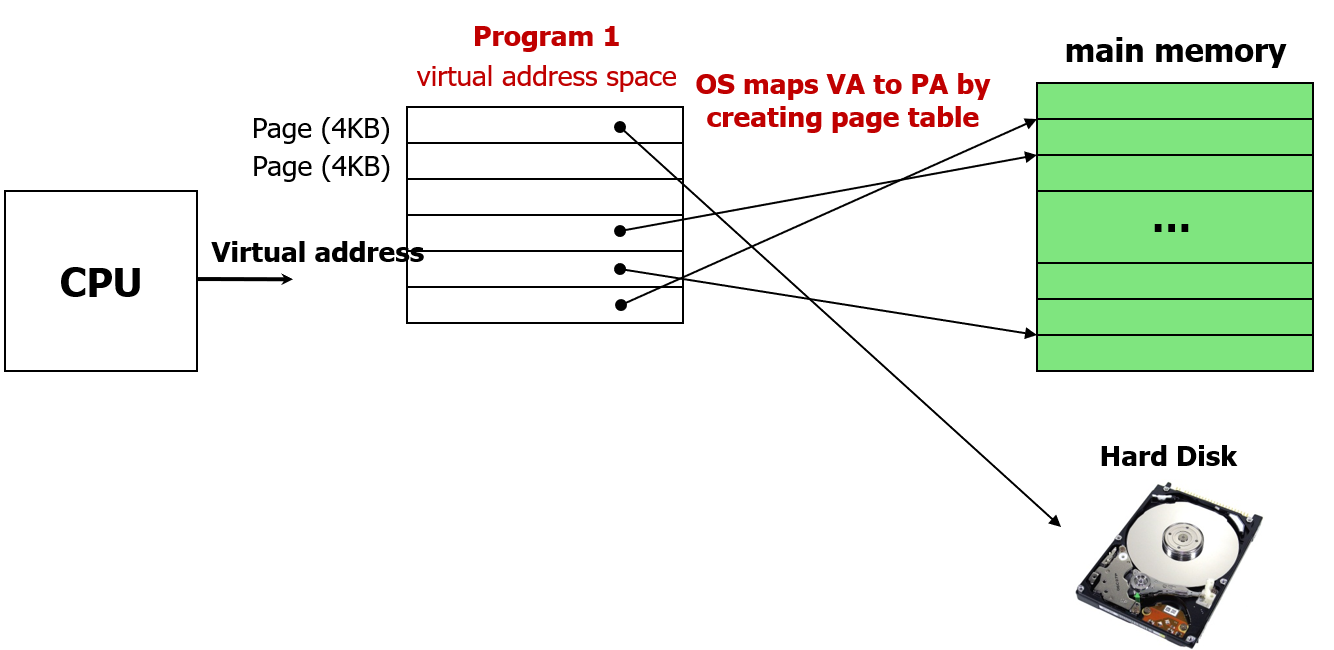
이 가상공간에는 진짜 데이터를 담을 수 없다.
따라서 CPU는 프로그램을 실행할 때 virtual address를 이용해서 접근하면, 진짜 데이터를 가져오거나 저장하기 위해서는 매핑된 main memory 위치에 가서 데이터를 가져와야 한다.
이를 위해서 운영체제가 만든 page table을 이용해서 운영체제가 직접 VA를 PA로 매핑해준다.
그리고 매핑은 page 단위로 이루어진다.
페이지 안에 있는 특정 byte가 여기저기로 가는 것이 아니라, virtual page 안에서 인접한 바이트들은 실제 physical page 안에서도 서로 인접해있다.
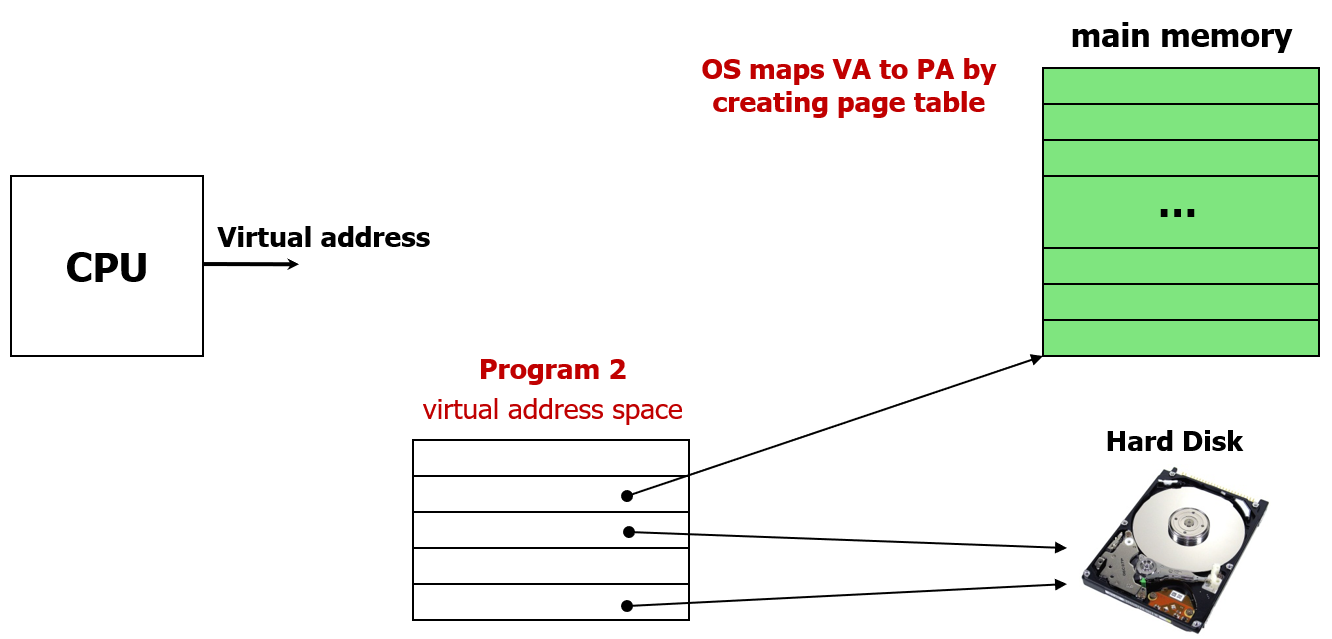
이 과정은 Program 2에 대해서도 동일하게 일어난다.
이 프로그램도 자신의 독립적인 virtual address space를 가지며, 이 공간은 page 단위로 쪼개져있다.
각각의 페이지는 운영체제가 만든 page table을 이용해서 운영체제가 VA를 PA로 매핑해주면 실제 데이터가 저장된 공간을 가리킬 수 있다.
페이지 테이블에는 페이지 단위로 매핑이 되어있으니, 각 페이지의 시작 주소만 페이지 테이블에 담기면된다.
주소 변환
이제 페이지 테이블을 통해서 어떻게 운영체제가 VA를 PA로 변환하는지 살펴보자.
주소를 변환한다는 건 실제로 존재하지 않는 가상 공간을, 물리적인 공간으로 매핑시켜준다는 것과 같다.
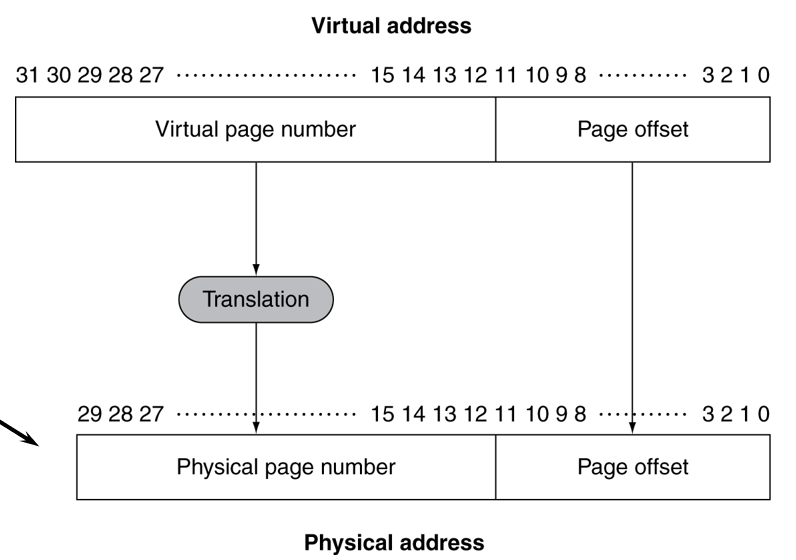
먼저 virtual address가 위와같이 32bit 주소로 존재한다.
이 주소의 길이는 CPU 코어가 생성한 공간이며, 보통 32bit (요즘은 64bit) 길이로 되어있다.
이 가상 공간이 가질 수 있는 크기는 2^32 byte = 4GB 공간이라고 생각할 수 있다.
이때 이 주소는 위 그림과 같이 2등분을 할 수 있다.
page 의 크기는 보통 4kb 로 잡는다고 하였으니 4kb = 4 * 1024 byte = 2^12 byte 이다.
따라서 페이지의 크기를 나타내는 bit 만큼 하위 비트를 빼면, page number를 알 수 있다.
이 하위비트가 page offset이 되어, 페이지 내에서 byte를 데이터를 구분하는 용도로 사용된다.
virtual address 에서는 32bit 에서 12bit를 빼면 20bit 길이의 virtual page number가 남는다.
밑에 있는 physical address에 대해서도 같은 작업을 거칠 수 있다.
그런데 physical address 는 그 주소의 길이가 꼭 virtual address와 같을 필요가 없다.
같아도 되고 달라도 된다. 가령 주어져있는 CPU가 메인 메모리랑 연결되는 핀 수에 의해서 제한이 생기거나, 메인 메모리의 크기에 의해 제약이 된다면 주소의 길이는 더 작을 수 있다.
위 그림과 같은 예시에서는 physical address가 30bit 이므로, 2^30 = 1GB 의 메모리를 나타낸다는 것을 알 수 있다.
그리고 이 physical 공간도 똑같은 page 단위로 구분할 수 있으므로, 12bit의 하위비트를 제하면, 남은 18bit 로 페이지 넘버를 구분할 수 있다.
이제 남은 일은 virtual address를 physical address로 변환하는 일만 남았다.
변환을 할 때는 translation이 그림에서 보는 것 과 같이 byte 단위로, 전체적으로 일어나는 게 아니라, 페이지 넘버에 대해서만 일어나고 있다.
하위 12bit는 어차피 동일하게 유지해야 하기 때문에, 하위 12bit 를 제외한 나머지만 변환하는 것이다.
virtual page number가 어떤 physical page number로 변환되는지만 보는 것이다.
Page Table
운영체제가 이걸 변환할 때, page table을 사용한다.
page table은 각각의 프로세스마다 존재한다.
(프로세스는 거칠게 말해서, 하드디스크에 들어있는 '프로그램'을 메모리에 올린 상태의 '프로그램'을 말한다.)
그리고 각 page table은 메인 메모리에 생성한다.
page table은 여러개의 entry로 구성되어있다.
이를 가리켜서 Page Table Entry (PTE) 라고 부른다.
그러면 페이지 테이블에 있는 특정 PTE에 접근할 때는 virtual page number를 통해서 접근한다.
그런데 page table 이 메인 메모리에 들어있다면, 페이지 테이블이 메인 메모리 상 어디에 있는지를 어떻게 알 수 있을까?
이 정보를 저장하기 위해서 Page Table Register 라는 특별한 레지스터에 페이지 테이블의 시작주소를 저장한다.
캐시에 대해서 Hit, Miss 2가지 경우가 있었듯이, 페이지에 대해서도 2가지 경우가 존재할 수 있다.
CPU가 원하는 페이지는 메인 메모리에 있을 수도, 메인 메모리에는 없고 Secondary Storage에 있을 수도 있다.
만약 메인 메모리에 있다면 해당 PTE에 접근해서 Physical Page Number를 알 수 있을 것이다.
만약 메인 메모리에 없다면 해당 PTE에 접근했을 때, 세컨더리 스토리지의 어디로 접근해야 해당 페이지가 있는지 알려준다.
(캐시처럼 Cache Miss 가 발생해서 캐시가 직접 데이터를 가져온 뒤, CPU에게 그 데이터를 알려주는, 일종의 recursive 방식이 아니라 iterative하게 대신 갈 수 있는 주소를 알려주는 것이다.)
세컨더리 스토리지 안에는 pysical page들을 담아줄 수 있는 공간이 있다.
이 공간을 Swap Space 라고 한다.
예시
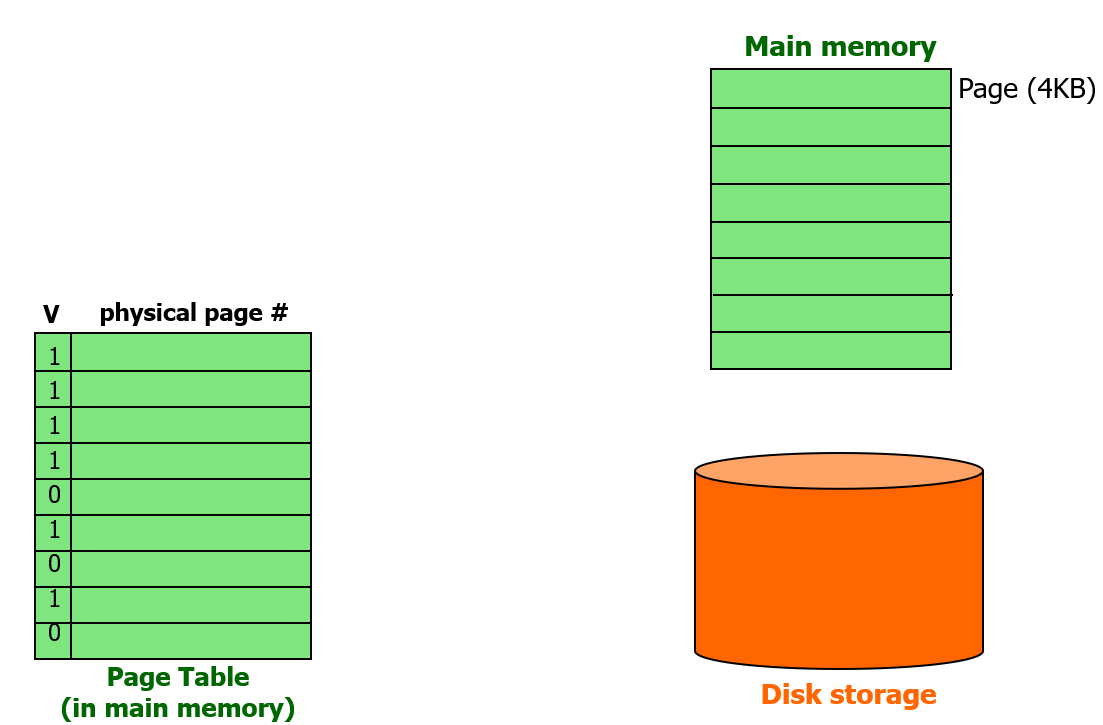
다음과 같이 컴퓨터가 구성되어 있다.
이때 CPU가 특정 메모리 데이터를 원한다고 생각해보자.
그 메모리 데이터를 접근하는 '주소'는 CPU 입장에서 virtual address 이다.
virtual address 는 원래 byte address 이지만, 이 주소에 대한 physical address 를 얻기 위해,
이 주소에서 페이지의 크기를 나타내는 bit만큼 하위 비트를 제외하고, 남은 나머지로 virutal page number 를 알아낸다.

이때 page table은 메모리에 들어있으므로, 페이지 테이블에 접근하기 위해 page table register 값을 읽어서 페이지 테이블 위치를 찾은 뒤, 그 위치로부터 entry 수만큼 떨어진 (오프셋) 위치에서 데이터를 읽는다.
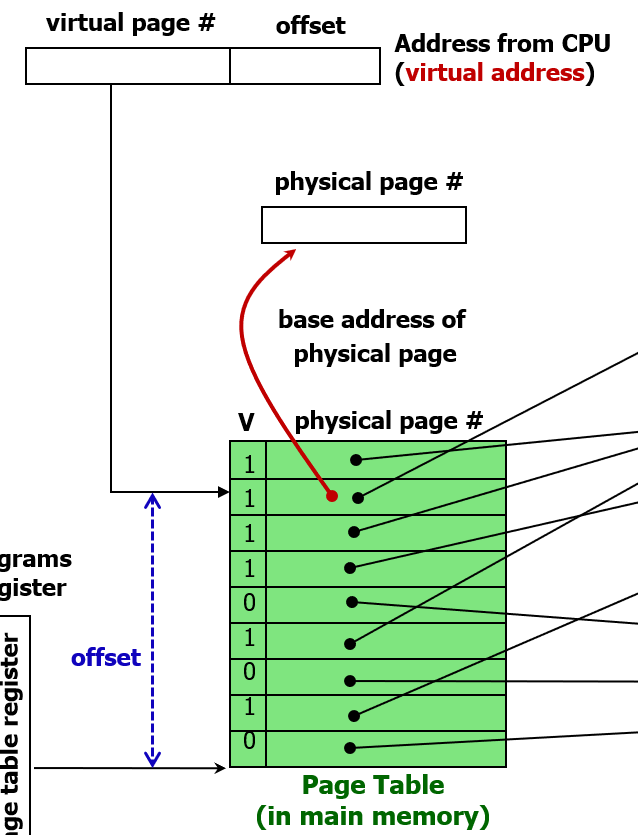
만약 PTE가 메인 메모리를 가리키고 있다면 (페이지가 메인 메모리에 들어있는 상황, valid 비트가 1) 이 테이블 엔트리에는 physical page number가 저장되어 있을 것이다.
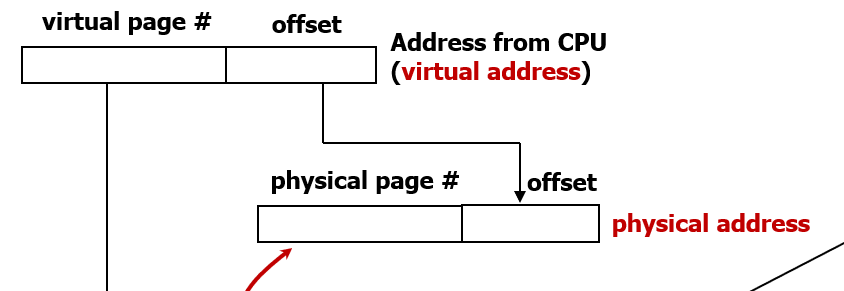
그러면 그 physical page number와 기존 주소의 offset을 합쳐서 (concatnate) physical address를 얻어낸다.
만약 valid 비트가 1이 아니라면 PTE에는 swap space의 어느 위치부터 얼마만큼 떨어진 엔트리에 내가 원하는 page 데이터가 들어있는지를 나타내는 정보가 저장되어있으니, 이를 읽어서 offset을 붙이고 disk storage에 접근한다.
(swap space의 주소 체계는 어떤지, swap space의 경우에도 마찬가지로 page number에 offset 을 붙여서 구하는지, GPT 말로는 케바케라고 함.)
'CS > 컴퓨터 구조' 카테고리의 다른 글
| [컴퓨터 구조] 28. Virtual Memory (3) - TLB 와 캐시 사이의 동작에 대한 고찰 (질문 정리) (0) | 2024.06.07 |
|---|---|
| [컴퓨터 구조] 27. Virtual Memory (2) - TLB (0) | 2024.06.07 |
| [컴퓨터 구조] 25. Cache (3) - 성능 개선 (0) | 2024.06.06 |
| [컴퓨터 구조] 24. Cache (2) - Direct-Mapped Cache (0) | 2024.06.04 |
| [컴퓨터 구조] 23. Cache (1) - 개요 (0) | 2024.06.03 |