
Critical Path (임계 경로)
Single Cycle MIPS 는 말 그대로 하나의 사이클에 모든 명령어를 처리하는 CPU이다.
add 명령어도, branch 명령어도, lw, sw 명령어도 모두 1Cycle에 처리한다.
이때 이 CPU의 성능을 빠르게 하려면 어떻게 할 수 있을까?
간단하게 생각할 수 있는 것은 1 Cycle의 주기를 짧게 가져가는 것이다. (주파수를 높이기)
그렇다면 단순히 주파수를 높이기만하면 성능도 그에 따라서 높아지기만 할까?
사실은 그렇지않다.
왜냐하면 Clock Cycle Time은 Critical Path에 의해 제약을 받기 때문이다.
(Critical Path == 명령어를 실행하는데 가장 긴 시간이 걸리는 경로)
현재 설계한 MIPS 회로에서 Critical Path 를 갖는 명령어는 lw 명령어이다.
명령어를 가져와서 해석한 뒤, 레지스터에서 base 주소를, immediate 필드에서 offset을 가져와 ALU로 더하여 메모리 주소를 계산하고, 계산한 주소로 접근해서 메모리의 값을 읽은 뒤, 그 값을 레지스터까지 갖고와서 쓰는 작업을 해야 실행이 끝난다.
반면 add 명령어는 명령어를 가져와서 해석한 뒤, 레지스터에서 rs, rt 를 가져와 ALU에서 더하고, 그 결과값을 곧바로 레지스터에 쓰면 실행이 끝난다.
임계 경로에 대해서 더 구체적으로 정의하자면,
입력이 변경되었을 때, 그 변경에 의해 출력값이 변경될 때까지 걸리는 시간을 delay(지연시간)라고 한다.
임계 경로는 최대 지연시간을 유도하는 경로를 말한다.
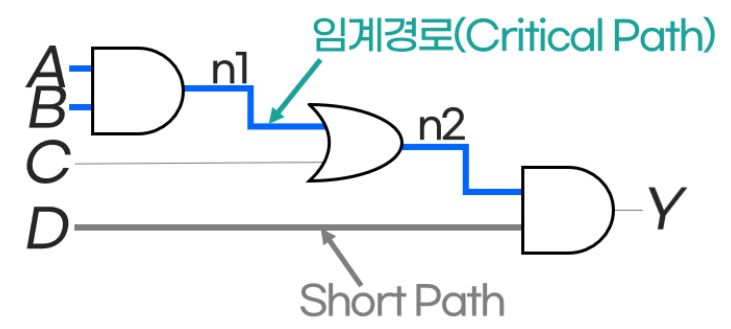
그림에서 and, or 게이트를 지나는 경로가, 단순히 선으로 연결된 경로보다 더 긴 지연시간을 가질 것이라는 것을 알 수 있다.
(사실 여기에서 의문이 생겼었다. 조합회로면 입력값이 바뀌었을 때 출력값이 즉시 바뀌지 않나, 왜 지연시간이 생길까? 교수님께 질문했을 때, and, or 과 같은 논리게이트는 트랜지스터로 구성되어있고, 각각의 트랜지스터는 서로 다른 저항을 갖고 있을 수 있기 때문에 단순 경로보다는 딜레이가 생길 수 밖에 없다고 한다.)
Single-Cycle MIPS의 임계 경로
그렇다면 Single-Cycle MIPS 에서의 임계 경로인 lw 명령어의 실행 경로를 따라가보자.
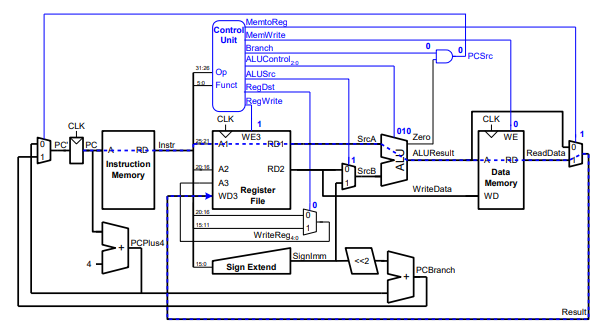
위 그림에서 파란색 선이 lw 명령어의 실행경로이다.
1. 프로그램 카운터에서 lw 명령어 주소를 가져온다.
그런데 클락 신호가 들어왔을 때 프로그램 카운터의 출력인 Q가 바로 나오지는 않는다.
PC에 클락 신호가 들어왔을 때 PC값의 출력인 Q가 나오기까지 걸리는 지연 시간을 T (pcq_PC) 라고 하자.
(propagation clock to q for PC의 줄임말이다.)
중요한 건 PC에서 클락으로부터 출력이 나오는데 딜레이가 존재한다는 것이다.
2. Instruction 메모리에서 lw 명령어를 가져온다.
PC에서 lw 명령어가 존재하는 메모리상 주소를 얻어왔으니, Instruction Memory에서 명령어 데이터를 가져와야 한다.
이때에도 딜레이가 발생하며, 이 딜레이시간을 T (mem) 이라고 하자.
3. lw 명령어를 해석한다.
lw명령어를 해석하는 과정에서
1. base address를 레지스터에서 읽어온다. (이 시간을 T (RF read) 라고 하자.)
2. offset을 sign extension 시킨다. (이 시간을 T (sext) 라고 하자.)
3. sign extension 시킨 값을 ALU Src로 넣기 위해 MUX를 통과한다. (이 시간을 T (mux) 라고 하자.)
lw 명령어를 해석하는데 걸리는 시간은 이 3가지 시간 중 가장 긴 시간이다.
이 3가지 작업은 동시에 일어나기 때문이다.
4. ALU에서 base address와 offset을 더한다.
ALU에서 메모리 주소를 계산한다. 이때 걸리는 딜레이를 T (ALU) 라고 하자.
5. ALU에서 계산한 주소를 토대로 메모리에 접근하여 값을 읽어온다.
당연히 이 시간에도 딜레이가 걸리며, 이 딜레이를 T (mem) 라고 하자.
6. 읽어온 메모리값을 레지스터에 쓰기 위해 MemToReg 신호를 받는 MUX를 통과한다.
이 딜레이 시간을 T (mux) 라고 하자.
7. 메모리값을 레지스터에 쓴다.
이때 메모리 값은 레지스터에 들어올 때, 다음 클락 신호보다 setup time 만큼은 일찍 도착해야 한다.
(setup time == 레지스터파일에 값을 쓸 때, write data 포트에 값이 있는 상태에서 Write Enable 신호가 켜져있으면 클락신호에 맞춰 값을 쓸텐데, 이때 클락 신호의 rising edge 보다 먼저 값이 준비되어 있어야 온전히 값이 쓰여진다. 플립플랍의 기본 동작이다.)
즉, 다음 클락신호가 시작하려면 setup time 만큼의 시간이 지나고 나서 다음 클락 신호가 시작해야 레지스터에 온전히 값을 쓸 수 있다는 뜻이므로 이 지연시간을 T (RF setup) 라고 하자.
그러면 Single-Cycle MIPS의 최종 Critical Path 에 대한 지연시간은 아래와 같이 계산할 수 있다.
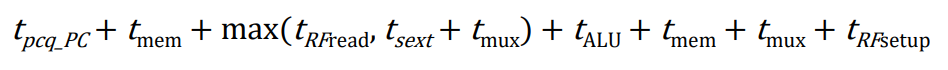
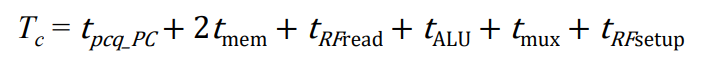
위 수식을 정리하면 아래 수식이 나온다.
1사이클의 주기는 최소한 이 시간(T c)보다는 길어야 한다.
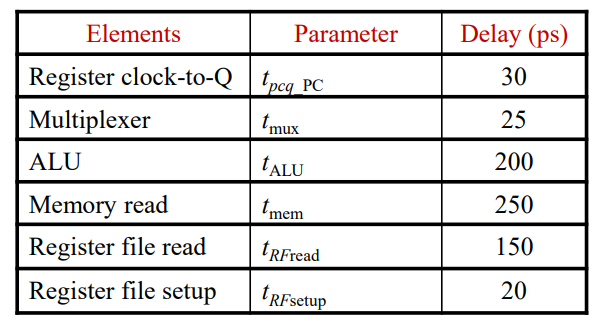
만약 각각의 딜레이 시간이 위 표와 같다면
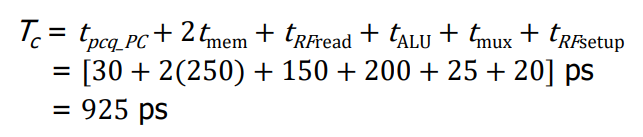
위 이미지와 같이 1사이클의 최소 주기 시간을 구할 수 있다.
만약 이런 CPU에서 1000억개의 명령어를 실행한다면 (1000억 == 10^11)
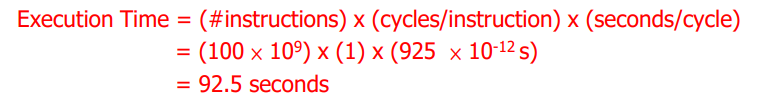
위와 같은 공식으로 총 실행시간을 계산할 수 있다.
Single Cycle 이기 때문에, 하나의 명령어를 실행하는데 1 사이클이 소모된다.
'CS > 컴퓨터 구조' 카테고리의 다른 글
| [컴퓨터 구조] 18. Pipeline MIPS (2) - Hazard (0) | 2024.05.30 |
|---|---|
| [컴퓨터 구조] 17. Pipeline MIPS (1) - 기본 아이디어 (1) | 2024.05.30 |
| [컴퓨터 구조] 15. Single Cycle MIPS - Control Unit (0) | 2024.05.29 |
| [컴퓨터 구조] 14. Single Cycle MIPS - 회로 정리 & ALU (0) | 2024.04.21 |
| [컴퓨터 구조] 13. Single Cycle MIPS - Execute (0) | 2024.04.19 |